
(Cover Photo: © Granger – “Lion Tamer”
The American animal tamer Clyde Beatty
performing in the 1930s.)
The processor’s caches are for the most part transparent to software. When enabled, instructions and data flow through these caches without the need for explicit software control. However, knowledge of the behavior of these caches may be useful in optimizing software performance. If not tamed wisely, these innocent cache mechanisms can certainly be a headache for novice C/C++ programmers.
First things first… Before I start with example C/C++ codes showing some common pitfalls and urban caching myths that lead to hard-to-trace bugs, I would like to make sure that we are all comfortable with ‘cache related terms’.
![]()
Terminology
In theory, CPU cache is a very high speed type of memory that is placed between the CPU and the main memory. (In practice, it is actually inside the processor, mostly operating at the speed of the CPU.) In order to improve latency of fetching information from the main memory, cache stores some of the information temporarily so that the next access to the same chunk of information is faster. CPU cache can store both ‘executable instructions’ and ‘raw data’.
“… from cache, instead of going back to memory.”
When the processor recognizes that an information being read from memory is cacheable, the processor reads an entire cache line into the appropriate cache slot (L1, L2, L3, or all). This operation is called a cache line fill. If the memory location containing that information is still cached when the processor attempts to access to it again, the processor can read that information from the cache instead of going back to memory. This operation is called a cache hit.
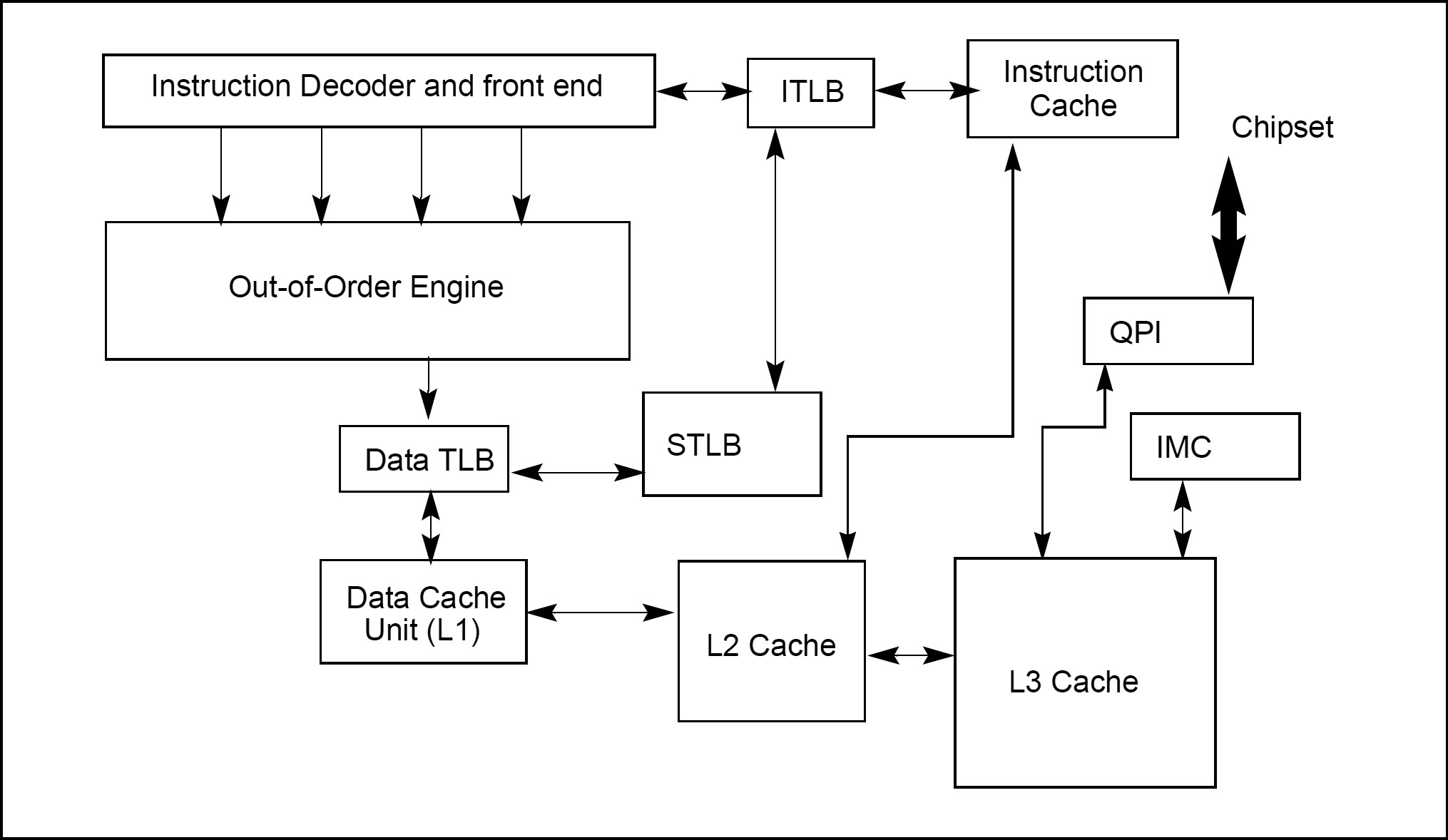
When the processor attempts to write an information to a cacheable area of memory, it first checks if a cache line for that memory location exists in the cache. If a valid cache line does exist, the processor (depending on the write policy currently in force) can write that information into the cache instead of writing it out to system memory. This operation is called a write hit. If a write misses the cache (that is, a valid cache line is not present for area of memory being written to), the processor performs a cache line fill, write allocation. Then it writes the information into the cache line and (depending on the write policy currently in force) can also write it out to memory. If the information is to be written out to memory, it is written first into the store buffer, and then written from the store buffer to memory when the system bus is available.
“… cached in shared state, between multiple CPUs.”
When operating in a multi-processor system, The Intel 64 and IA-32 architectures have the ability to keep their internal caches consistent both with system memory and with the caches in other processors on the bus. For example, if one processor detects that another processor intends to write to a memory location that it currently has cached in shared state, the processor in charge will invalidate its cache line forcing it to perform a cache line fill the next time it accesses the same memory location. This type of internal communication between the CPUs is called snooping.
And finally, translation lookaside buffer (TLB) is a special type of cache designed for speeding up address translation for virtual memory related operations. It is a part of the chip’s memory-management unit (MMU). TLB keeps track of where virtual pages are stored in physical memory, thus speeds up ‘virtual address to physical address’ translation by storing a lookup page-table.
So far so good… Let’s start coding, and shed some light on urban caching myths. 😉
![]()
How to Guarantee Caching in C/C++
To be honest, under normal conditions, there is absolutely no way to guarantee that the variable you defined in C/C++ will be cached. CPU cache and write buffer management are out of scope of the C/C++ language, actually.
Most programmers assume that declaring a variable as constant will automatically turn it into something cacheable!
const int nVar = 33;
As a matter of fact, doing so will tell the C/C++ compiler that it is forbidden for the rest of the code to modify the variable’s value, which may or may not lead to a cacheable case. By using a const, you simply increase the chance of getting it cached. In most cases, compiler will be able to turn it into a cache hit. However, we can never be sure about it unless we debug and trace the variable with our own eyes.
![]()
How to Guarantee No Caching in C/C++
An urban myth states that, by using volatile type qualifier, it is possible to guarantee that a variable can never be cached. In other words, this myth assumes that it might be possible to disable CPU caching features for specific C/C++ variables in your code!
volatile int nVar = 33;
Actually, defining a variable as volatile prevents compiler from optimizing it, and forces the compiler to always refetch (read once again) the value of that variable from memory. But, this may or may not prevent it from caching, as volatile has nothing to do with CPU caches and write buffers, and there is no standard support for these features in C/C++.
So, what happens if we declare the same variable without const or volatile?
int nVar = 33;
Well, in most cases, your code will be executed and cached properly. (Still not guaranteed though.) But, one thing for sure… If you write ‘weird’ code, like the following one, then you are asking for trouble!
int nVar = 33;
while (nVar == 33)
{
. . .
}
In this case, if the optimization is enabled, C/C++ compiler may assume that nVar never changes (always set to 33) due to no reference of nVar in loop’s body, so that it can be replaced with true for the sake of optimizing while condition.
while (true)
{
. . .
}
A simple volatile type qualifier fixes the problem, actually.
volatile int nVar = 33;
![]()
What about Pointers?
Well, handling pointers is no different than taking care of simple integers.
Case #1:
Let’s try to evaluate the while case mentioned above once again, but this time with a Pointer.
int nVar = 33;
int *pVar = (int*) &nVar;
while (*pVar)
{
. . .
}
In this case,
![]() nVar is declared as an integer with an initial value of 33,
nVar is declared as an integer with an initial value of 33,
![]() pVar is assigned as a Pointer to nVar,
pVar is assigned as a Pointer to nVar,
![]() the value of nVar (33) is gathered using pointer pVar, and this value is used as a conditional statement in while loop.
the value of nVar (33) is gathered using pointer pVar, and this value is used as a conditional statement in while loop.
On the surface there is nothing wrong with this code, but if aggressive C/C++ compiler optimizations are enabled, then we might be in trouble. – Yes, some compilers are smarter than others! 😉
Due to fact that the value of pointer variable has never been modified and/or accessed through the while loop, compiler may decide to optimize the frequently called conditional statement of the loop. Instead of fetching *pVar (value of nVar) each time from the memory, compiler might think that keeping this value in a register might be a good idea. This is known as ‘software caching’.
Now, we have two problems here:
1.) Values in registers are ‘hardware cached’. (CPU cache can store both instructions and data, remember?) If somehow, software cached value in the register goes out of sync with the original one in memory, the CPU will never be aware of this situation and will keep on caching the old value from hardware cache. – CPU cache vs software cache. What a mess!
2.) Since the value of nVar has never been modified, the compiler can even go one step further by assuming that the check against *pVar can be casted to a Boolean value, due to its usage as a conditional statement. As a result of this optimization, the code above might turn into this:
int nVar = 33;
int *pVar = (int*) &nVar;
if (*pVar)
{
while (true)
{
. . .
}
}
Both problems detailed above, can be fixed by using a volatile type qualifier. Doing so prevents the compiler from optimizing *pVar, and forces the compiler to always refetch the value from memory, rather than using a compiler-generated software cached version in registers.
int nVar = 33;
volatile int *pVar = (int*) &nVar;
while (*pVar)
{
. . .
}
Case #2:
Here comes an another tricky example about Pointers.
const int nVar = 33; int *pVar = (int*) &nVar; *pVar = 0;
In this case,
![]() nVar is declared as a ‘constant’ variable,
nVar is declared as a ‘constant’ variable,
![]() pVar is assigned as a Pointer to nVar,
pVar is assigned as a Pointer to nVar,
![]() and, pVar is trying to change the ‘constant’ value of nVar!
and, pVar is trying to change the ‘constant’ value of nVar!
Under normal conditions, no C/C++ programmer would make such a mistake, but for the sake of clarity let’s assume that we did.
If aggressive optimization is enabled, due to fact that;
a.) Pointer variable points to a constant variable,
b.) Value of pointer variable has never been modified and/or accessed,
some compilers may assume that the pointer can be optimized for the sake of software caching. So, despite *pVar = 0, the value of nVar may never change.
Is that all? Well, no… Here comes the worst part! The value of nVar is actually compiler dependent. If you compile the code above with a bunch of different C/C++ compilers, you will notice that in some of them nVar will be set to 0, and in some others set to 33 as a result of ‘ambiguous’ code compilation/execution. Why? Simply because, every compiler has its own standards when it comes to generating code for ‘constant’ variables. As a result of this inconsistent situation, even with just a single constant variable, things can easily get very complicated.
Fixing such brute-force compiler optimization issues is quite easy. You can get rid of const type qualifier,
constint nVar = 33;
or, replace const with volatile type qualifier,
volatile int nVar = 33;
or, use both!
const volatile int nVar = 33;
![]()
Rule of Thumb
Using volatile is absolutely necessary in any situation where compiler could make wrong assumptions about a variable keeping its value constant, just because a function does not change it itself. Not using volatile would create very complicated bugs due to the executed code that behaves as if the value did not change – (It did, indeed).
If code that works fine, somehow fails when you;
![]() Use cross compilers,
Use cross compilers,
![]() Port code to a different compiler,
Port code to a different compiler,
![]() Enable compiler optimizations,
Enable compiler optimizations,
![]() Enable interrupts,
Enable interrupts,
make sure that your compiler is NOT over-optimizing variables for the sake of software caching.
Please keep in mind that, volatile has nothing to do with CPU caches and write buffers, and there is no standard support for these features in C/C++. These are out of scope of the C/C++ language, and must be solved by directly interacting with the CPU core!
![]()
Getting Hands Dirty via Low-Level CPU Cache Control
Software driven hardware cache management is possible. There are special ‘privileged’ Assembler instructions to clean, invalidate, flush cache(s), and synchronize the write buffer. They can be directly executed from privileged modes. (User mode applications can control the cache through system calls only.) Most compilers support this through built-in/intrinsic functions or inline Assembler.
The Intel 64 and IA-32 architectures provide a variety of mechanisms for controlling the caching of data and instructions, and for controlling the ordering of reads/writes between the processor, the caches, and memory.
These mechanisms can be divided into two groups:
![]() Cache control registers and bits: The Intel 64 and IA-32 architectures define several dedicated registers and various bits within control registers and page/directory-table entries that control the caching system memory locations in the L1, L2, and L3 caches. These mechanisms control the caching of virtual memory pages and of regions of physical memory.
Cache control registers and bits: The Intel 64 and IA-32 architectures define several dedicated registers and various bits within control registers and page/directory-table entries that control the caching system memory locations in the L1, L2, and L3 caches. These mechanisms control the caching of virtual memory pages and of regions of physical memory.
![]() Cache control and memory ordering instructions: The Intel 64 and IA-32 architectures provide several instructions that control the caching of data, the ordering of memory reads and writes, and the prefetching of data. These instructions allow software to control the caching of specific data structures, to control memory coherency for specific locations in memory, and to force strong memory ordering at specific locations in a program.
Cache control and memory ordering instructions: The Intel 64 and IA-32 architectures provide several instructions that control the caching of data, the ordering of memory reads and writes, and the prefetching of data. These instructions allow software to control the caching of specific data structures, to control memory coherency for specific locations in memory, and to force strong memory ordering at specific locations in a program.
How does it work?
The Cache Control flags and Memory Type Range Registers (MTRRs) operate hierarchically for restricting caching. That is, if the CD flag of control register 0 (CR0) is set, caching is prevented globally. If the CD flag is clear, the page-level cache control flags and/or the MTRRs can be used to restrict caching.
If there is an overlap of page-level and MTRR caching controls, the mechanism that prevents caching has precedence. For example, if an MTRR makes a region of system memory uncacheable, a page-level caching control cannot be used to enable caching for a page in that region. The converse is also true; that is, if a page-level caching control designates a page as uncacheable, an MTRR cannot be used to make the page cacheable.
In cases where there is a overlap in the assignment of the write-back and write-through caching policies to a page and a region of memory, the write-through policy takes precedence. The write-combining policy -which can only be assigned through an MTRR or Page Attribute Table (PAT)– takes precedence over either write-through or write-back. The selection of memory types at the page level varies depending on whether PAT is being used to select memory types for pages.
![]()
CPU Control Registers
Generally speaking, control registers (CR0, CR1, CR2, CR3, and CR4) determine operating mode of the processor and the characteristics of the currently executing task. These registers are 32 bits in all 32-bit modes and compatibility mode. In 64-bit mode, control registers are expanded to 64 bits.
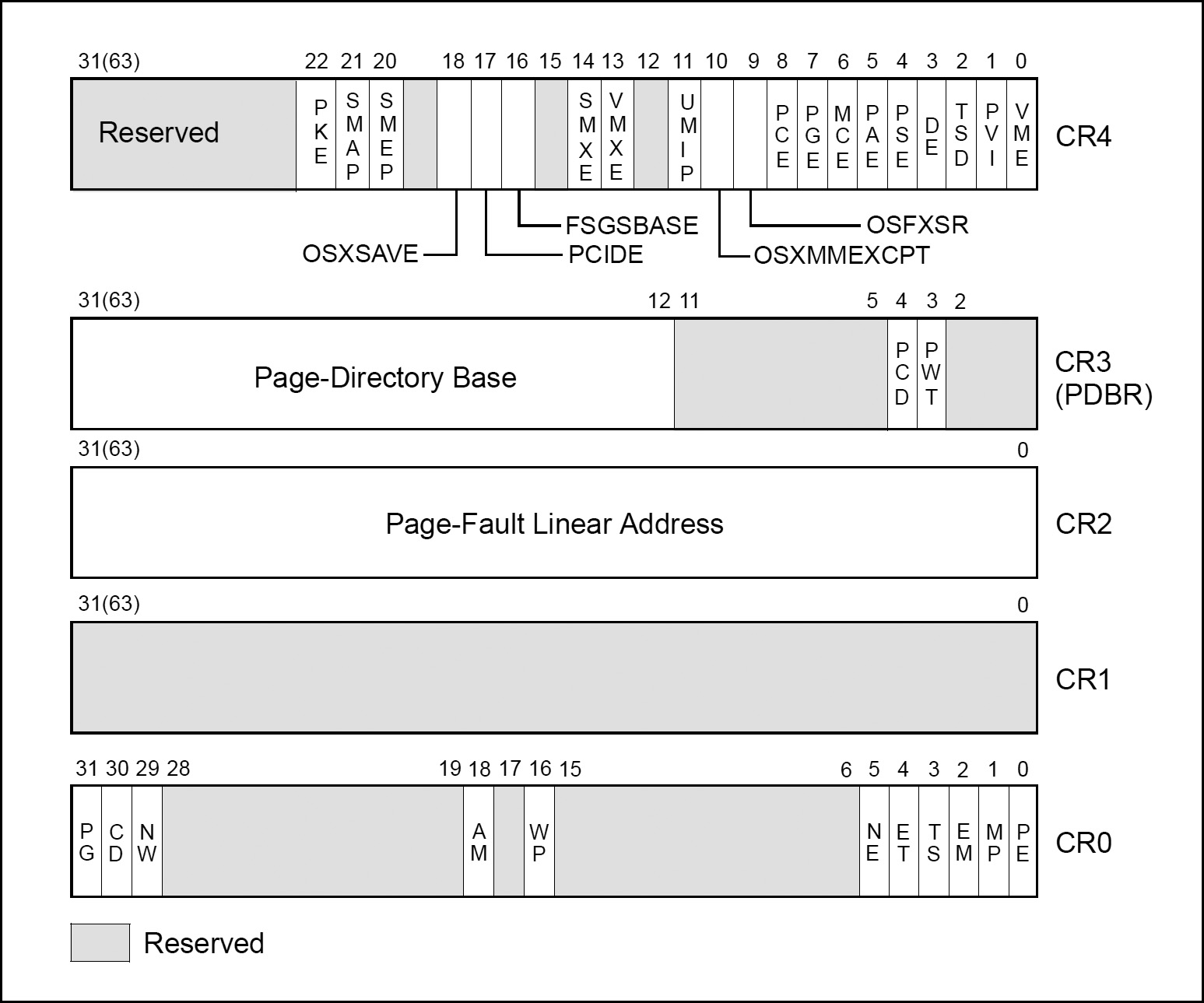
The MOV CRn instructions are used to manipulate the register bits. These instructions can be executed only when the current privilege level is 0.
| Instruction | 64-bit Mode | Legacy Mode | Description |
|---|---|---|---|
| MOV r32, CR0–CR7 | – | Valid | Move control register to r32. |
| MOV r64, CR0–CR7 | Valid | – | Move extended control register to r64. |
| MOV r64, CR8 | Valid | – | Move extended CR8 to r64. |
| MOV CR0–CR7, r32 | – | Valid | Move r32 to control register. |
| MOV CR0–CR7, r64 | Valid | – | Move r64 to extended control register. |
| MOV CR8, r64 | Valid | – | Move r64 to extended CR8. |
The Intel 64 and IA-32 architectures provide the following cache-control registers and bits for use in enabling or restricting caching to various pages or regions in memory:
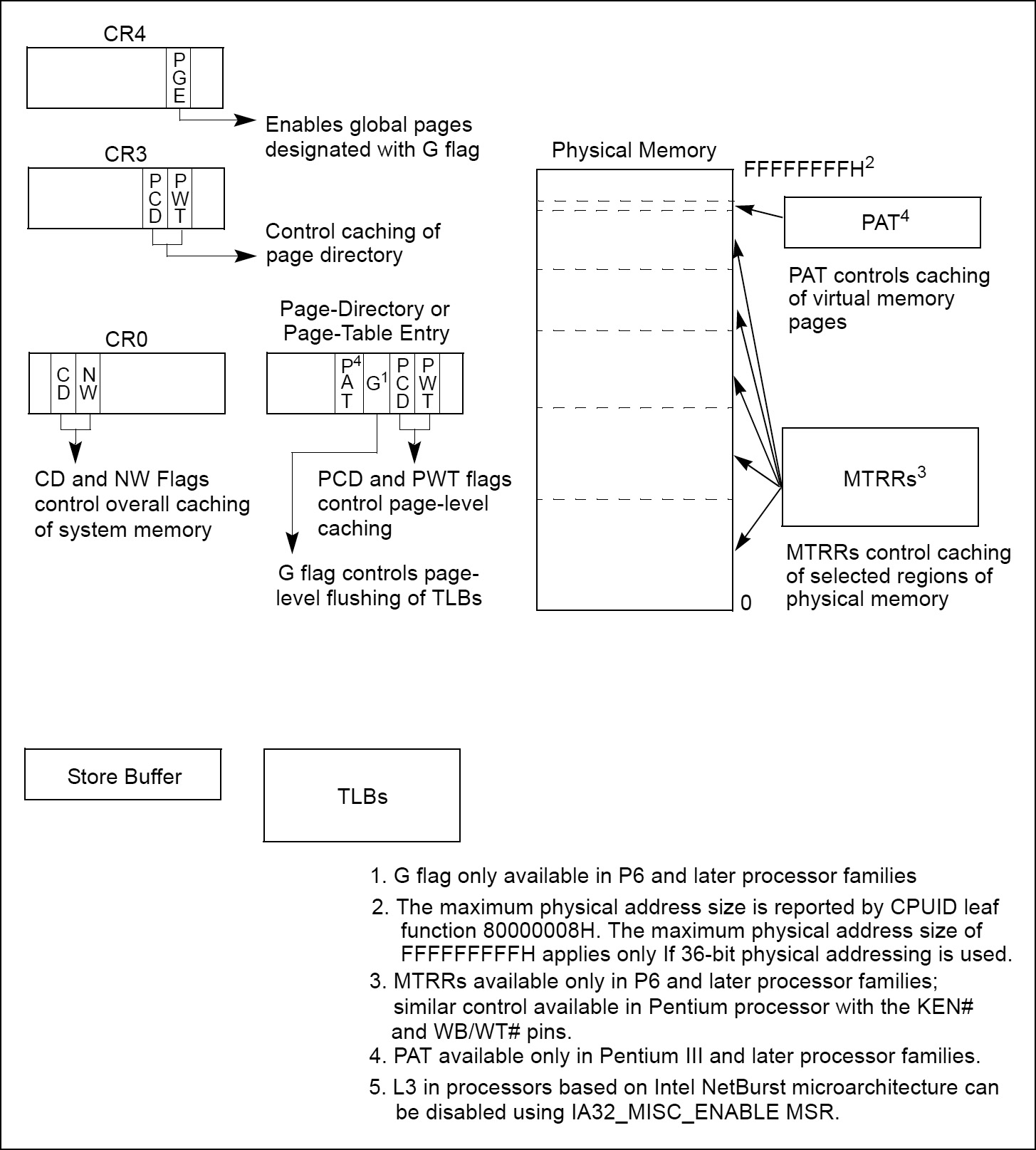
![]() CD flag (bit 30 of control register CR0): Controls caching of system memory locations. If the CD flag is clear, caching is enabled for the whole of system memory, but may be restricted for individual pages or regions of memory by other cache-control mechanisms. When the CD flag is set, caching is restricted in the processor’s caches (cache hierarchy) for the P6 and more recent processor families. With the CD flag set, however, the caches will still respond to snoop traffic. Caches should be explicitly flushed to insure memory coherency. For highest processor performance, both the CD and the NW flags in control register CR0 should be cleared. To insure memory coherency after the CD flag is set, the caches should be explicitly flushed. (Setting the CD flag for the P6 and more recent processor families modify cache line fill and update behaviour. Also, setting the CD flag on these processors do not force strict ordering of memory accesses unless the MTRRs are disabled and/or all memory is referenced as uncached.)
CD flag (bit 30 of control register CR0): Controls caching of system memory locations. If the CD flag is clear, caching is enabled for the whole of system memory, but may be restricted for individual pages or regions of memory by other cache-control mechanisms. When the CD flag is set, caching is restricted in the processor’s caches (cache hierarchy) for the P6 and more recent processor families. With the CD flag set, however, the caches will still respond to snoop traffic. Caches should be explicitly flushed to insure memory coherency. For highest processor performance, both the CD and the NW flags in control register CR0 should be cleared. To insure memory coherency after the CD flag is set, the caches should be explicitly flushed. (Setting the CD flag for the P6 and more recent processor families modify cache line fill and update behaviour. Also, setting the CD flag on these processors do not force strict ordering of memory accesses unless the MTRRs are disabled and/or all memory is referenced as uncached.)
![]() NW flag (bit 29 of control register CR0): Controls the write policy for system memory locations. If the NW and CD flags are clear, write-back is enabled for the whole of system memory, but may be restricted for individual pages or regions of memory by other cache-control mechanisms.
NW flag (bit 29 of control register CR0): Controls the write policy for system memory locations. If the NW and CD flags are clear, write-back is enabled for the whole of system memory, but may be restricted for individual pages or regions of memory by other cache-control mechanisms.
![]() PCD and PWT flags (in paging-structure entries): Control the memory type used to access paging structures and pages.
PCD and PWT flags (in paging-structure entries): Control the memory type used to access paging structures and pages.
![]() PCD and PWT flags (in control register CR3): Control the memory type used to access the first paging structure of the current paging-structure hierarchy.
PCD and PWT flags (in control register CR3): Control the memory type used to access the first paging structure of the current paging-structure hierarchy.
![]() G (global) flag in the page-directory and page-table entries: Controls the flushing of TLB entries for individual pages.
G (global) flag in the page-directory and page-table entries: Controls the flushing of TLB entries for individual pages.
![]() PGE (page global enable) flag in control register CR4: Enables the establishment of global pages with the G flag.
PGE (page global enable) flag in control register CR4: Enables the establishment of global pages with the G flag.
![]() Memory type range registers (MTRRs): Control the type of caching used in specific regions of physical memory.
Memory type range registers (MTRRs): Control the type of caching used in specific regions of physical memory.
![]() Page Attribute Table (PAT) MSR: Extends the memory typing capabilities of the processor to permit memory types to be assigned on a page-by-page basis.
Page Attribute Table (PAT) MSR: Extends the memory typing capabilities of the processor to permit memory types to be assigned on a page-by-page basis.
![]() 3rd Level Cache Disable flag (bit 6 of IA32_MISC_ENABLE MSR): Allows the L3 cache to be disabled and enabled, independently of the L1 and L2 caches. (Available only in processors based on Intel NetBurst microarchitecture)
3rd Level Cache Disable flag (bit 6 of IA32_MISC_ENABLE MSR): Allows the L3 cache to be disabled and enabled, independently of the L1 and L2 caches. (Available only in processors based on Intel NetBurst microarchitecture)
![]() KEN# and WB/WT# pins (Pentium processor): Allow external hardware to control the caching method used for specific areas of memory. They perform similar (but not identical) functions to the MTRRs in the P6 family processors.
KEN# and WB/WT# pins (Pentium processor): Allow external hardware to control the caching method used for specific areas of memory. They perform similar (but not identical) functions to the MTRRs in the P6 family processors.
![]() PCD and PWT pins (Pentium processor): These pins (which are associated with the PCD and PWT flags in control register CR3 and in the page-directory and page-table entries) permit caching in an external L2 cache to be controlled on a page-by-page basis, consistent with the control exercised on the L1 cache of these processors. (The P6 and more recent processor families do not provide these pins because the L2 cache is embedded in the chip package.)
PCD and PWT pins (Pentium processor): These pins (which are associated with the PCD and PWT flags in control register CR3 and in the page-directory and page-table entries) permit caching in an external L2 cache to be controlled on a page-by-page basis, consistent with the control exercised on the L1 cache of these processors. (The P6 and more recent processor families do not provide these pins because the L2 cache is embedded in the chip package.)
![]()
How to Manage CPU Cache using Assembly Language
The Intel 64 and IA-32 architectures provide several instructions for managing the L1, L2, and L3 caches. The INVD and WBINVD instructions are privileged instructions and operate on the L1, L2 and L3 caches as a whole. The PREFETCHh, CLFLUSH and CLFLUSHOPT instructions and the non-temporal move instructions (MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, and MOVNTPD) offer more granular control over caching, and are available to all privileged levels.
The INVD and WBINVD instructions are used to invalidate the contents of the L1, L2, and L3 caches. The INVD instruction invalidates all internal cache entries, then generates a special-function bus cycle that indicates that external caches also should be invalidated. The INVD instruction should be used with care. It does not force a write-back of modified cache lines; therefore, data stored in the caches and not written back to system memory will be lost. Unless there is a specific requirement or benefit to invalidating the caches without writing back the modified lines (such as, during testing or fault recovery where cache coherency with main memory is not a concern), software should use the WBINVD instruction.
In theory, WBINVD instruction performs the following steps:
WriteBack(InternalCaches); Flush(InternalCaches); SignalWriteBack(ExternalCaches); SignalFlush(ExternalCaches); Continue;
The WBINVD instruction first writes back any modified lines in all the internal caches, then invalidates the contents of both the L1, L2, and L3 caches. It ensures that cache coherency with main memory is maintained regardless of the write policy in effect (that is, write-through or write-back). Following this operation, the WBINVD instruction generates one (P6 family processors) or two (Pentium and Intel486 processors) special-function bus cycles to indicate to external cache controllers that write-back of modified data followed by invalidation of external caches should occur. The amount of time or cycles for WBINVD to complete will vary due to the size of different cache hierarchies and other factors. As a consequence, the use of the WBINVD instruction can have an impact on interrupt/event response time.
The PREFETCHh instructions allow a program to suggest to the processor that a cache line from a specified location in system memory be prefetched into the cache hierarchy.
The CLFLUSH and CLFLUSHOPT instructions allow selected cache lines to be flushed from memory. These instructions give a program the ability to explicitly free up cache space, when it is known that cached section of system memory will not be accessed in the near future.
The non-temporal move instructions (MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, and MOVNTPD) allow data to be moved from the processor’s registers directly into system memory without being also written into the L1, L2, and/or L3 caches. These instructions can be used to prevent cache pollution when operating on data that is going to be modified only once before being stored back into system memory. These instructions operate on data in the general-purpose, MMX, and XMM registers.
![]()
How to Disable Hardware Caching
To disable the L1, L2, and L3 caches after they have been enabled and have received cache fills, perform the following steps:
1.) Enter the no-fill cache mode. (Set the CD flag in control register CR0 to 1 and the NW flag to 0.
2.) Flush all caches using the WBINVD instruction.
3.) Disable the MTRRs and set the default memory type to uncached or set all MTRRs for the uncached memory type.
The caches must be flushed (step 2) after the CD flag is set to insure system memory coherency. If the caches are not flushed, cache hits on reads will still occur and data will be read from valid cache lines.
The intent of the three separate steps listed above address three distinct requirements:
a.) Discontinue new data replacing existing data in the cache,
b.) Ensure data already in the cache are evicted to memory,
c.) Ensure subsequent memory references observe UC memory type semantics. Different processor implementation of caching control hardware may allow some variation of software implementation of these three requirements.
Setting the CD flag in control register CR0 modifies the processor’s caching behaviour as indicated, but setting the CD flag alone may not be sufficient across all processor families to force the effective memory type for all physical memory to be UC nor does it force strict memory ordering, due to hardware implementation variations across different processor families. To force the UC memory type and strict memory ordering on all of physical memory, it is sufficient to either program the MTRRs for all physical memory to be UC memory type or disable all MTRRs.
![]()
References:
![]() Richard Blum, “Professional Assembly Language”, Wrox Publishing – (2005)
Richard Blum, “Professional Assembly Language”, Wrox Publishing – (2005)
![]() Keith Cooper & Linda Torczon, “Engineering A Compiler”, Morgan Kaufmann, 2nd Edition – (2011)
Keith Cooper & Linda Torczon, “Engineering A Compiler”, Morgan Kaufmann, 2nd Edition – (2011)
![]() Alexey Lyashko, “Mastering Assembly Programming”, Packt Publishing Limited – (2017)
Alexey Lyashko, “Mastering Assembly Programming”, Packt Publishing Limited – (2017)
![]() “Intel® 64 and IA-32 Architectures Optimization Reference Manual” – (April 2018)
“Intel® 64 and IA-32 Architectures Optimization Reference Manual” – (April 2018)
![]() “Intel® 64 and IA-32 Architectures Software Developer’s Manual: Basic Architecture” – (November 2018)
“Intel® 64 and IA-32 Architectures Software Developer’s Manual: Basic Architecture” – (November 2018)
![]() “Intel® 64 and IA-32 Architectures Software Developer’s Manual: Instruction Set Reference A-Z” – (November 2018)
“Intel® 64 and IA-32 Architectures Software Developer’s Manual: Instruction Set Reference A-Z” – (November 2018)
![]() “Intel® 64 and IA-32 Architectures Software Developer’s Manual: System Programming Guide” – (November 2018)
“Intel® 64 and IA-32 Architectures Software Developer’s Manual: System Programming Guide” – (November 2018)
![]() “Intel® 64 and IA-32 Architectures Software Developer’s Manual: Model-Specific Registers” – (November 2018)
“Intel® 64 and IA-32 Architectures Software Developer’s Manual: Model-Specific Registers” – (November 2018)