Yet another masterpiece from Tuncay Talayman, simply and humbly one of the most gifted talents in the video game industry. This time he portraits me as a GPU burner sorcerer, which is literally true.
“Innovation Engineering” is a great influence on the growth and survival of today’s world. As a method for solving technology and business problems to innovate, adapt, and enter new markets using the expertise in emerging technologies, it is an essential tool for creative minds.
Much like every other industry in the world, video game development industry is open to new ideas and products more than ever. Actually, it has never been more critical. New technologies emerge, as do new business models. Thanks to innovation culture, video game development process has become more than classic software engineering by evolving into modern innovation engineering.
The latest release of The Occult is a meticulous combination of software and innovation engineering. In order to maximize productivity and efficiency, outside the box thinking was vital. I had to come up with creative and unorthodox problem solving methods. So, rather than waiting for a-ha! moments, I relied on cross-disciplinary research and practices for creativity, and classic engineering methodology for productivity; simply harnessing the best of both worlds… And it worked, charmingly!
The Occult version 2022.2 is released!
The Occult, a virtual gameplay programming ecosystem for Unreal Engine, is now available for both Intel and ARM architectures by offering improved cross-platform compatibility, exciting new features, enhancements, and a few bug fixes. As usual, all commercial and personal video game development projects that I am currently involved in will benefit from the new/enhanced features available in this release.
New Architecture
Multiprocessing System Architecture: User-defined number of virtual processors can perform sync/async operations at the same time. Multiprocessing read/write operations on shared code/memory are 100% thread-safe at both virtual and physical access level.
Multiple Stacks for Multiple Processors: A private stack is assigned for each vCPU, and a public stack is shared among all processors. The public stack is mainly used for level-scope variables, and can be accessed via Index/Data bus. Contrary to the public stack, private stacks do not use Occult’s bus architecture anymore. They are hardwired to parent vCPUs for exceptional low-latency access!
Virtual/Native Code Switching: Instant code switching at instruction-precision level of detail creates an opportunity to inject native C++ code into virtual Assembly code and vice versa, while creating endless possibilities for hardcore code optimization.
Blazingly fast 32-bit text/numerical Tag driven instance management.
Enhancements
All coprocessors (Trigger, Flagger, Pooler) are enhanced to take advantage of new multiprocessing system.
New speed/size optimized Flagger node graph search algorithm is written in 92 bytes (yes, ninety-two!) using inline Assembly; small enough to flatter physical cache.
Enhanced native Intel architecture support for PC.
Enhanced native ARM architecture support for Apple Silicon Macs and Nintendo Switch.
Improved Game Executable Compatibility
Windows 10 – (21H2)
Windows 11 – (22H2)
macOS Big Sur 11.7 – (Intel/Apple Silicon)
macOS Monterey 12.6 – (Apple Silicon only)
iOS 14
iOS 15
iOS 16
Nintendo Switch
Improved C++ Code Compatibility
Unreal Engine 4 – (4.26.2, 4.27.2)
Unreal Engine 5 – (5.0.3)
Improved C++ Development Environment Compatibility
Availability:The Occult is not available for public use. It is a proprietary software.
Copyright Notice:The Occult VM architecture and all related tools are conceived, designed, implemented and owned by Mert Börü. The Occult logo is designed and crafted by Tuncay Talayman.
In terms of productivity, efficiency, and profitability, coding via versatile range of “cross-platform” tools is a must for 21st century video game developer.
However, regarding Unreal Engine’s cross-platform features, debugging, fine-tuning and optimizing game code simultaneously on multiple platforms can sometimes be a real headache even for veteran developers. It is a complex, time-consuming and error-prone task by its very nature. And, this is where The Occult’s latest release comes into play…
The Occult version 2022.1 is released!
I am truly excited to announce the latest release of The Occult. It is now available for both Intel and ARM architectures by offering improved platform compatibility, exciting new features, various enhancements, and a few bug fixes. As of today, all commercial and personal video game development projects that I am currently involved in will benefit from the new/enhanced features available in this release.
Enhancements
New native ARM architecture support for Apple Silicon Macs and Nintendo Switch.
Enhanced native Intel architecture support for PC.
New speed/size optimized bytecode generation using inline Intel and ARM Assembly routines.
Enhanced 64-bit cross-platform visual debugger/logger for VM, Stack, and Database.
New speed/size optimized C++ data structures for Trigger coprocessor: Definition, Action, and Component.
New level manager architecture design & implementation.
New VM firmware routines for asynchronous Actor/Component management.
Enhanced OOR driven ALU instruction set implementation.
Improved Game Executable Compatibility
Windows 10
Windows 11
macOS Big Sur – (Intel/Apple Silicon)
macOS Monterey – (Apple Silicon only)
iOS 14
iOS 15
Nintendo Switch
Improved C++ Code Compatibility
Unreal Engine 4 – (4.26.2, 4.27.2)
Unreal Engine 5 – (EA2)
Improved C++ Development Environment Compatibility
Microsoft Visual Studio 2019 version 16.11.9
Microsoft Visual Studio 2022 version 17.0.5
Apple Xcode version 13.2.1
JetBrains Rider for Unreal Engine 2021.3.1
JetBrains Rider 2022.1 – (will be released in Q1 2022)
Bug Fixes
Level World offset implementation.
Stack driven smart VM pointer architecture for object type detection.
Stack driven object pointer validation.
Availability:The Occult is not available for public use. It is a proprietary software.
Copyright Notice:The Occult VM architecture and all related tools are conceived, designed, implemented and owned by Mert Börü. The Occult logo is designed and crafted by Tuncay Talayman.
A Synchronous/Asynchronous Virtual Machine Architecture
for Unreal Engine
Mert Börü
Video Game Developer
mertboru@gmail.com
Abstract
The “Occult” virtual machine architecture is a cross-platform C++ middleware designed and implemented for Unreal Engine. The primary feature of the Occult is to deliver super-optimized AAA grade games. By adding a very thin-layer on top of Unreal Engine C++ API, the Occult provides a virtual microcomputer architecture with a synchronous/asynchronous 64-bit CPU, various task specific 32-bit coprocessors, and a modern assembly language gameplay programming ecosystem for handling real-time memory/asset management and in-game abstract object/data streaming. It can be used as a standalone solution or as a supplementary tool for existing Blueprint/C++ projects.
It is no secret that, due to nature of modern OOP guidelines, Unreal Engine C++ source code is full of “virtual functions”. It is also no secret that, calling a virtual function is inherently slower than calling a non-virtual function… So, what’s the catch?
A non-virtual call is simply a jump (JMP) to a compiled-in pointer. On the other hand, a virtual call requires at least an extra indexed dereference, and sometimes a fixup addition, which is stored in a lookup table known as Virtual Method Table (VMT). This is simply why a virtual call is always slower than a non-virtual call.
To avoid this overhead, compilers usually steer clear of VMT whenever the call can be resolved at compile time. However, due to complex nature of Inheritence based class structures used in modern game engines, using VMT is unavoidable in most cases.
Virtual Method Table (VMT)
An object’s VMT (also known as vtable) contains the addresses of the object’s dynamically bound methods. Method calls are performed by fetching the method’s address from the object’s virtual method table.
C++ compiler creates a separate VMT for each class. When an object is created, a virtual pointer (VPTR) to this table is added as a hidden member of this object. The compiler also generates hidden code in the constructors of each class to initialize new object’s VPTR to the address of its class’ virtual method table.
The virtual method table is same for all objects belonging to the same class, and is therefore typically shared between them. Objects belonging to type-compatible classes in an inheritance hierarchy will have virtual method tables with the same layout.
Tip: The C++ standards do not mandate exactly how dynamic dispatch must be implemented, but compilers generally use minor variations on the same basic model. The VMT is generally a good performance trade-off to achieve dynamic dispatch, but there are alternatives, such as Binary Tree Dispatch (BTD), with higher performance but different costs.
Speaking of hidden codes and VMTs in the constructors of each class, each C++ object should also contain additional information about its type. An object’s data type is a crucial information in terms of casting.
Run-Time Type Information (RTTI)
RTTI is a feature of the C++ programming language that exposes information about an object’s data type at runtime. It can apply to simple data types, such as integers and characters, or to generic types.
Run-Time Type Information is available only for classes that are polymorphic, which means they have at least one virtual method. In practice, this is not a limitation because base classes must have a virtual destructor to allow objects of derived classes to perform proper cleanup if they are deleted from a base pointer.
RTTI is used in three main C++ language elements:
The dynamic_cast operator: Used for conversion of polymorphic types.
The typeidoperator: Used for identifying the exact type of an object.
The type_info class: Used to hold the type information returned by the typeid operator.
In order to perform cast-related operations listed above, RTTI heavily uses VMT. For example, given an object of a polymorphic class, a type_info object can be obtained through the use of the typeid operator. In principle, this is a simple operation which involves finding the VMT, through that finding the most-derived class object of which the object is part, and then extracting a pointer to the type_info object from that object’s virtual function table (or equivalent).
In terms of performance, using the dynamic_cast operator is more expensive than type_info. Given a pointer to an object of a polymorphic class, a cast to a pointer to another base subobject of the same derived class object can be done using a dynamic_cast. In principle, this operation involves finding the VMT, through that finding the most-derived class object of which the object is part, and then using type information associated with that object to determine if the conversion (cast) is allowed, and finally performing any required adjustments of the pointer. In principle, this checking involves the traversal of a data structure describing the base classes of the most derived class. Thus, the run-time cost of a dynamic_cast may depend on the relative positions in the class hierarchy of the two classes involved.
Tip: In the original C++ design, Bjarne Stroustrup did not include RTTI, because he thought this mechanism was often misused.
Hacking VMT and RTTI Information using UE C++
In order to gather “header” information (that contains VMT and RTTI data) in an Unreal Engine C++ class/object, I have written the following LogClassHeader() C++ function using Visual Studio 2019 version 16.3.8 for Unreal Engine version 4.23.1.
void UDebugCore::LogClassHeader(void* const pThis, size_t nSize)
{
FString fsClassName = "NULL";
FString fsObjectName = "NULL";
UObject* const pCastedToUObject = (UObject*)(pThis);
void** const pCastedToHeader = reinterpret_cast<void**>(pThis);
if (pCastedToUObject)
{
fsClassName = pCastedToUObject->GetClass()->GetName();
fsObjectName = pCastedToUObject->GetName();
}
if (pCastedToHeader)
{
for (size_t i = 0; i < nSize / sizeof(void*); i++)
{
MACRO_PRINTF("Pointer[%04zu] = 0x%p", i, pCastedToHeader[i])
}
}
}
This function has 2 input parameters:
pThis: Object to extract Class Header Info from nSize:Size of Header
Calling the function is very easy. You simply insert your call into the constructor of the class that you would like to hack. For example, the following code gathers C++ header information of <APlayerControllerThirdPerson> class.
When you run the code, all pointers that are available (and used) in the header of <APlayerControllerThirdPerson> will be listed. And, in case you need, instance name and class type is stored in fsObjectName and fsClassName variables, as a bonus.
So, what do these numbers mean? Well, all these pointers are addresses of the virtual functions, followed by some of the member variables. In order to understand which is which, we need to decipher the structure of the data set.
Here comes the tricky part! With each and every update to Visual Studio C++ compiler, the structure tends to get updated as well. In other words, the header structure of a C++ class changes with each major compiler update. Try to think of it as a “living organism”. As I’m typing this sentence now, a new update with a new C++ header structure may be on its way. So, it is up to you (!) to analyze what’s going on under the hood.
Good news is, we can gather <template> information about C++ class header structure from the official Microsoft patent documents! Although they are not up-to-date, I think it is a good practice to start the investigation using the source of information itself.
Here is some of the Microsoft patents which describe various parts of C++ implementation used in Visual Studio:
US Patent #5410705:“Method for generating an object data structure layout for a class in a compiler for an object-oriented programming language”
US Patent #5617569:“Method and system for implementing pointers to members in a compiler for an object-oriented programming language”
US Patent #5754862:“Method and system for accessing virtual base classes”
US Patent #5297284:“Method and system for implementing virtual functions and virtual base classes and setting a this pointer for an object-oriented programming language”
US Patent #5371891:“Method for object construction in a compiler for an object-oriented programming language”
US Patent #5603030:“Method and system for destruction of objects using multiple destructor functions in an object-oriented computer system”
So, what I’m offering is, good old-fashioned “reverse engineering”.
– “Is such a challenge worth it?”
– “Um, yes!… If it doesn’t break you, it can make you.”
References:
Bjarne Stroustrup, “A History of C++: 1979—1991”, p. 50 – (March 1993)
Keith Cooper & Linda Torczon, “Engineering A Compiler”, Morgan Kaufmann, 2nd Edition – (2011)
Microsoft Visual Studio Documentation, “C++ Run-Time Type Information” – (November 2016)
“Technical Report on C++ Performance”, OpenRCE.org – (September 2006)
“Reversing Microsoft Visual C++: Classes, Methods and RTTI”, OpenRCE.org – (September 2006)
When I appreciate ‘the moment’, happiness follows. Happiness is often in the little things, and year 2018 has offered me a bunch of them. Sincerely thankful and grateful for all the little things I have been given this year… Now is the time to cherish the ‘moments of joy’ by sharing a few snapshots, in no particular order.
Unreal Fest Europe 2018
A three day event designed exclusively for game creators using Unreal Engine, with speakers drawn from Epic, platform owners and some of the leading development studios in Europe took place in Berlin, April 24-27. Such a great opportunity for meeting old friends, and making new ones. – Thank you Epic!
It is no secret that Nintendo is using Unreal Engine 4 for their current and upcoming line of Switch games. As an Unreal Engine developer, I had the privilege of visiting Nintendo European Research & Development (NERD) in Paris for a 1-on-1 meeting. Due to usual Nintendo regulations, I’m not allowed to share any kind of information about the top-notch engineering stuff that I had witnessed, but that can’t prevent me from telling you how much I was impressed. All I can say is “WOW!” 😉
I have great admiration and respect for Japanese business culture, which is genuinely represented in Paris. Thank you very much for your kind hospitality!
IndieCade Europe 2018
IndieCade continues to support the development of independent games by organizing a series of international events to promote the future of indie games. This year, we had the 3rd installment of European organization, and it is getting better and bigger each year. I love the indie spirit. No matter how experienced you are, we always have new things to learn from each other.
From my perspective, the most iconic moment of the event was meeting and chatting with Japanese game developer Hidetaka Suehiro (aka “Swery65”), the designer of The Last Blade (1997) and The Last Blade 2 (1998). Both games were released by SNK for Neo Geo MVS – my all time favourite 2D console.
So, guess what we talked about… Fighting games? No… Neo Geo? No… Game design? No… Believe it or not, our main topic was “best hookah (water pipe) cafés in Istanbul”. I’m simply amazed to discover that he knows Istanbul better than me. Swery65 is full of surprises!
mini-RAAT Meetings @ MakerEvi
Try to imagine an unscheduled last-minute “members only” meeting, hosting crème de la crème IT professionals ranging from ex-Microsoft engineers to gifted video game artists, acclaimed musicians, network specialists, and many other out of this world talents, in addition to a bunch of academicians with hell of titles and degrees! So, what on earth is the common denominator that brings these gentlemen together, at least once or twice a year? Retrocomputing, for sure… Bundled with fun, laughter and joy! 🙂
Special thanks to our host, MakerEvi – a professional ‘Maker Movement Lab’ dedicated to contemporary DIY culture, fueled by the artisan spirit and kind hospitality of The Gürevins. An exceptional blend of local perspective and global presence.
Dila’s Graduation
This year, my dear daughter has graduated from Collège Sainte Pulchérie YN2000 with DELF B1 level French diploma, a compulsory certificate to follow studies in the French higher education system. Being a hardworking student, she has passed national high school entrance exam, and is currently attending Lycée Français Saint-Michel. – “I am proud of you… Bonne chance, ma chérie!”
“The bond that links your true family is not one of blood, but of respect and joy in each other’s life.”
– Richard Bach
Family is a ‘sanctuary’ for the individual. If we are blessed enough to have a loving, happy, and peaceful family, we should be grateful every day for it. It is where we learn to feel the value of being part of something greater than ourselves. Love is a powerful thing; we just have to be open to it.
Life is a Celebration
For all the moments I have enjoyed and to all my dear friends & members of my family who made those meaningful moments possible, I would like to propose a toast. Would you like to join me for a glass of absinthe, so that we keep on chasing our ‘green fairies’ together and forever? 😉
The processor’s caches are for the most part transparent to software. When enabled, instructions and data flow through these caches without the need for explicit software control. However, knowledge of the behavior of these caches may be useful in optimizing software performance. If not tamed wisely, these innocent cache mechanisms can certainly be a headache for novice C/C++ programmers.
First things first… Before I start with example C/C++ codes showing some common pitfalls and urban caching myths that lead to hard-to-trace bugs, I would like to make sure that we are all comfortable with ‘cache related terms’.
Terminology
In theory, CPU cache is a very high speed type of memory that is placed between the CPU and the main memory. (In practice, it is actually inside the processor, mostly operating at the speed of the CPU.) In order to improve latency of fetching information from the main memory, cache stores some of the information temporarily so that the next access to the same chunk of information is faster. CPU cache can store both ‘executable instructions’ and ‘raw data’.
“… from cache, instead of going back to memory.”
When the processor recognizes that an information being read from memory is cacheable, the processor reads an entire cache line into the appropriate cache slot (L1, L2, L3, or all). This operation is called a cache line fill. If the memory location containing that information is still cached when the processor attempts to access to it again, the processor can read that information from the cache instead of going back to memory. This operation is called a cache hit.
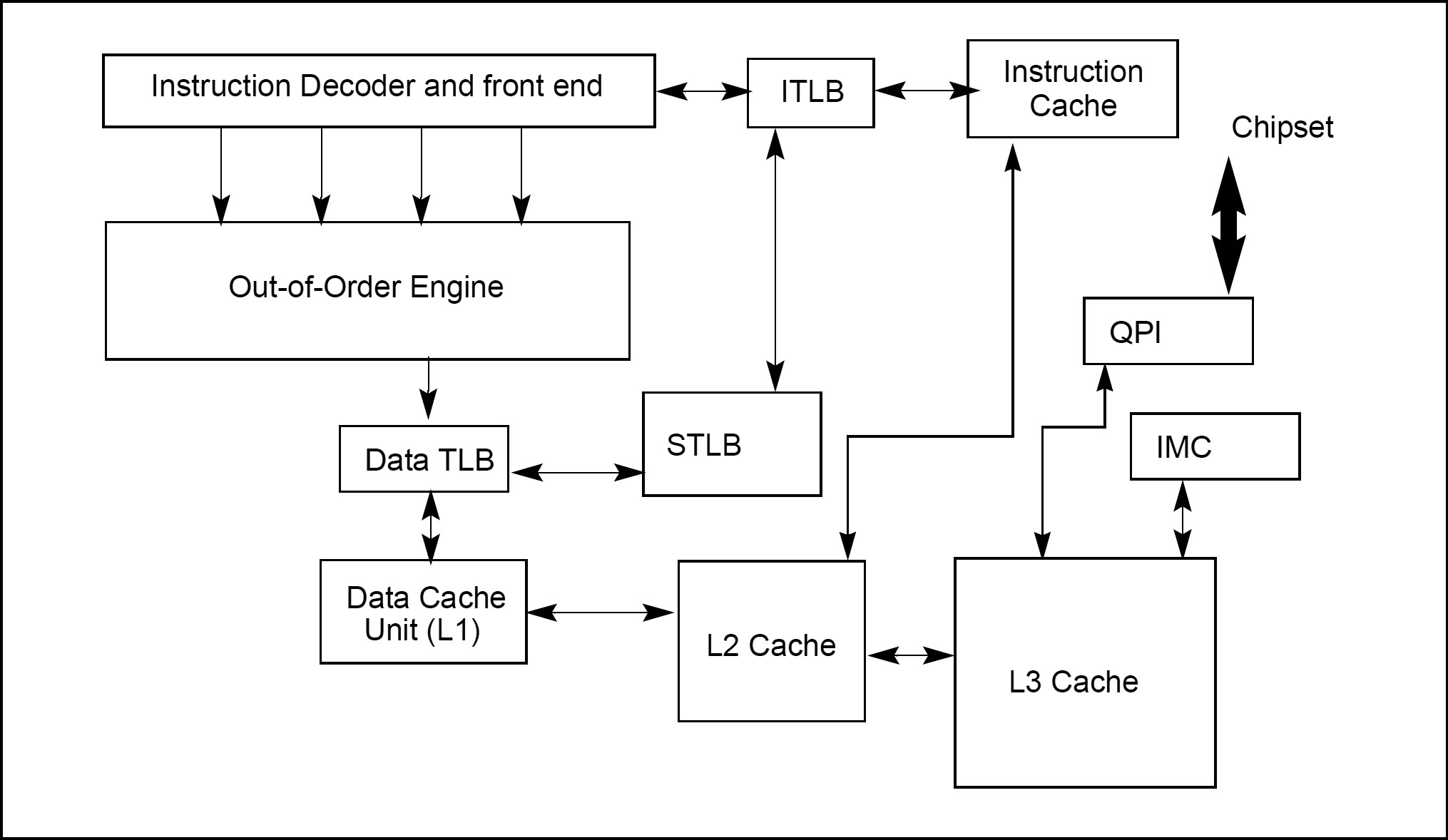
Hierarchical Cache Structure of the Intel Core i7 Processors
When the processor attempts to write an information to a cacheable area of memory, it first checks if a cache line for that memory location exists in the cache. If a valid cache line does exist, the processor (depending on the write policy currently in force) can write that information into the cache instead of writing it out to system memory. This operation is called a write hit. If a write misses the cache (that is, a valid cache line is not present for area of memory being written to), the processor performs a cache line fill, write allocation. Then it writes the information into the cache line and (depending on the write policy currently in force) can also write it out to memory. If the information is to be written out to memory, it is written first into the store buffer, and then written from the store buffer to memory when the system bus is available.
“… cached in shared state, between multiple CPUs.”
When operating in a multi-processor system, The Intel 64 and IA-32 architectures have the ability to keep their internal caches consistent both with system memory and with the caches in other processors on the bus. For example, if one processor detects that another processor intends to write to a memory location that it currently has cached in shared state, the processor in charge will invalidate its cache line forcing it to perform a cache line fill the next time it accesses the same memory location. This type of internal communication between the CPUs is called snooping.
And finally, translation lookaside buffer (TLB) is a special type of cache designed for speeding up address translation for virtual memory related operations. It is a part of the chip’s memory-management unit (MMU). TLB keeps track of where virtual pages are stored in physical memory, thus speeds up ‘virtual address to physical address’ translation by storing a lookup page-table.
So far so good… Let’s start coding, and shed some light on urban caching myths. 😉
How to Guarantee Caching in C/C++
To be honest, under normal conditions, there is absolutely no way to guarantee that the variable you defined in C/C++ will be cached. CPU cache and write buffer management are out of scope of the C/C++ language, actually.
Most programmers assume that declaring a variable as constant will automatically turn it into something cacheable!
const int nVar = 33;
As a matter of fact, doing so will tell the C/C++ compiler that it is forbidden for the rest of the code to modify the variable’s value, which may or may not lead to a cacheable case. By using a const, you simply increase the chance of getting it cached. In most cases, compiler will be able to turn it into a cache hit. However, we can never be sure about it unless we debug and trace the variable with our own eyes.
How to Guarantee No Caching in C/C++
An urban myth states that, by using volatile type qualifier, it is possible to guarantee that a variable can never be cached. In other words, this myth assumes that it might be possible to disable CPU caching features for specific C/C++ variables in your code!
volatile int nVar = 33;
Actually, defining a variable as volatile prevents compiler from optimizing it, and forces the compiler to always refetch (read once again) the value of that variable from memory. But, this may or may not prevent it from caching, as volatile has nothing to do with CPU caches and write buffers, and there is no standard support for these features in C/C++.
So, what happens if we declare the same variable without const or volatile?
int nVar = 33;
Well, in most cases, your code will be executed and cached properly. (Still not guaranteed though.) But, one thing for sure… If you write ‘weird’ code, like the following one, then you are asking for trouble!
int nVar = 33;
while (nVar == 33)
{
. . .
}
In this case, if the optimization is enabled, C/C++ compiler may assume that nVar never changes (always set to 33) due to no reference of nVar in loop’s body, so that it can be replaced with true for the sake of optimizing while condition.
while (true)
{
. . .
}
A simple volatile type qualifier fixes the problem, actually.
volatile int nVar = 33;
What about Pointers?
Well, handling pointers is no different than taking care of simple integers.
Case #1:
Let’s try to evaluate the while case mentioned above once again, but this time with a Pointer.
int nVar = 33;
int *pVar = (int*) &nVar;
while (*pVar)
{
. . .
}
In this case,
nVar is declared as an integer with an initial value of 33, pVar is assigned as a Pointer to nVar, the value of nVar (33) is gathered using pointer pVar, and this value is used as a conditional statement in while loop.
On the surface there is nothing wrong with this code, but if aggressive C/C++ compiler optimizations are enabled, then we might be in trouble. – Yes, some compilers are smarter than others! 😉
Due to fact that the value of pointer variable has never been modified and/or accessed through the while loop, compiler may decide to optimize the frequently called conditional statement of the loop. Instead of fetching *pVar (value of nVar) each time from the memory, compiler might think that keeping this value in a register might be a good idea. This is known as ‘software caching’.
Now, we have two problems here:
1.) Values in registers are ‘hardware cached’. (CPU cache can store both instructions and data, remember?) If somehow, software cached value in the register goes out of sync with the original one in memory, the CPU will never be aware of this situation and will keep on caching the old value from hardware cache. – CPU cache vs software cache. What a mess!
Tip: Is that scenario really possible?! – To be honest, no. During the compilation process, the C/C++ compiler should be clever enough to foresee that problem, if-and-only-if*pVar has never been modified in loop’s body. However, as a programmer, it is our responsibility to make sure that compiler should be given ‘properly written code’ with no ambiguous logic/data treatment. So, instead of keeping our fingers crossed and expecting miracles from the compiler, we should take complete control over the direction of our code. Before making assumptions on how our code will be compiled, we should first make sure that our code is crystal clear.
2.) Since the value of nVar has never been modified, the compiler can even go one step further by assuming that the check against *pVar can be casted to a Boolean value, due to its usage as a conditional statement. As a result of this optimization, the code above might turn into this:
int nVar = 33;
int *pVar = (int*) &nVar;
if (*pVar)
{
while (true)
{
. . .
}
}
Both problems detailed above, can be fixed by using a volatile type qualifier. Doing so prevents the compiler from optimizing *pVar, and forces the compiler to always refetch the value from memory, rather than using a compiler-generated software cached version in registers.
int nVar = 33;
volatile int *pVar = (int*) &nVar;
while (*pVar)
{
. . .
}
Case #2:
Here comes an another tricky example about Pointers.
const int nVar = 33;
int *pVar = (int*) &nVar;
*pVar = 0;
In this case,
nVar is declared as a ‘constant’ variable, pVar is assigned as a Pointer to nVar, and, pVar is trying to change the ‘constant’ value of nVar!
Under normal conditions, no C/C++ programmer would make such a mistake, but for the sake of clarity let’s assume that we did.
If aggressive optimization is enabled, due to fact that;
a.) Pointer variable points to a constant variable,
b.) Value of pointer variable has never been modified and/or accessed,
some compilers may assume that the pointer can be optimized for the sake of software caching. So, despite *pVar = 0, the value of nVarmay never change.
Is that all? Well, no… Here comes the worst part! The value of nVar is actually compiler dependent. If you compile the code above with a bunch of different C/C++ compilers, you will notice that in some of them nVar will be set to 0, and in some others set to 33 as a result of ‘ambiguous’ code compilation/execution. Why? Simply because, every compiler has its own standards when it comes to generating code for ‘constant’ variables. As a result of this inconsistent situation, even with just a single constant variable, things can easily get very complicated.
Tip: The best way to fix ‘cache oriented compiler optimization issues’, is to change the way you write code, with respect to tricky compiler specific optimizations in mind. Try to write crystal clear code. Never assume that compiler knows programming better than you. Always debug, trace, and check the output… Be prepared for the unexpected!
Fixing such brute-force compiler optimization issues is quite easy. You can get rid of const type qualifier,
const int nVar = 33;
or, replace const with volatile type qualifier,
volatile int nVar = 33;
or, use both!
const volatile int nVar = 33;
Tip: ‘const volatile’ combination is commonly used on embedded systems, where hardware registers that can be read and are updated by the hardware, cannot be altered by software. In such cases, reading hardware register’s value is never cached, always refetched from memory.
Rule of Thumb
Using volatile is absolutely necessary in any situation where compiler could make wrong assumptions about a variable keeping its value constant, just because a function does not change it itself. Not using volatile would create very complicated bugs due to the executed code that behaves as if the value did not change – (It did, indeed).
If code that works fine, somehow fails when you;
Use cross compilers, Port code to a different compiler, Enable compiler optimizations, Enable interrupts,
make sure that your compiler is NOT over-optimizing variables for the sake of software caching.
Please keep in mind that, volatile has nothing to do with CPU caches and write buffers, and there is no standard support for these features in C/C++. These are out of scope of the C/C++ language, and must be solved by directly interacting with the CPU core!
Getting Hands Dirty via Low-Level CPU Cache Control
Software driven hardware cache management is possible. There are special ‘privileged’ Assembler instructions to clean, invalidate, flush cache(s), and synchronize the write buffer. They can be directly executed from privileged modes. (User mode applications can control the cache through system calls only.) Most compilers support this through built-in/intrinsic functions or inline Assembler.
The Intel 64 and IA-32 architectures provide a variety of mechanisms for controlling the caching of data and instructions, and for controlling the ordering of reads/writes between the processor, the caches, and memory.
These mechanisms can be divided into two groups:
Cache control registers and bits: The Intel 64 and IA-32 architectures define several dedicated registers and various bits within control registers and page/directory-table entries that control the caching system memory locations in the L1, L2, and L3 caches. These mechanisms control the caching of virtual memory pages and of regions of physical memory.
Cache control and memory ordering instructions: The Intel 64 and IA-32 architectures provide several instructions that control the caching of data, the ordering of memory reads and writes, and the prefetching of data. These instructions allow software to control the caching of specific data structures, to control memory coherency for specific locations in memory, and to force strong memory ordering at specific locations in a program.
How does it work?
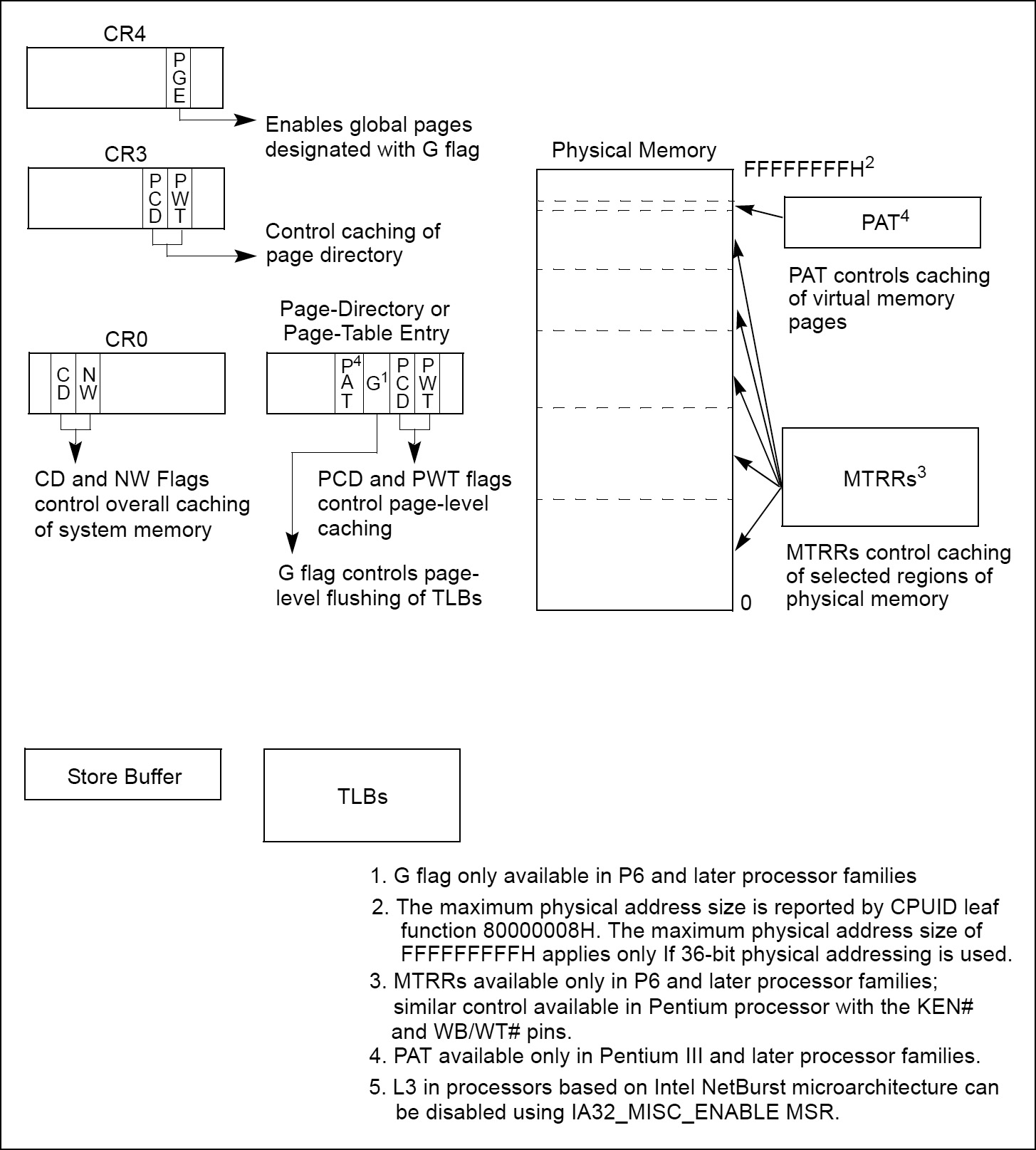
The Cache Control flags and Memory Type Range Registers (MTRRs) operate hierarchically for restricting caching. That is, if the CD flag of control register 0 (CR0) is set, caching is prevented globally. If the CD flag is clear, the page-level cache control flags and/or the MTRRs can be used to restrict caching.
Tip: The memory type range registers (MTRRs) provide a mechanism for associating the memory types with physical-address ranges in system memory. They allow the processor to optimize operations for different types of memory such as RAM, ROM, frame-buffer memory, and memory-mapped I/O devices. They also simplify system hardware design by eliminating the memory control pins used for this function on earlier IA-32 processors and the external logic needed to drive them.
If there is an overlap of page-level and MTRR caching controls, the mechanism that prevents caching has precedence. For example, if an MTRR makes a region of system memory uncacheable, a page-level caching control cannot be used to enable caching for a page in that region. The converse is also true; that is, if a page-level caching control designates a page as uncacheable, an MTRR cannot be used to make the page cacheable.
In cases where there is a overlap in the assignment of the write-back and write-through caching policies to a page and a region of memory, the write-through policy takes precedence. The write-combining policy -which can only be assigned through an MTRR or Page Attribute Table (PAT)– takes precedence over either write-through or write-back. The selection of memory types at the page level varies depending on whether PAT is being used to select memory types for pages.
Tip: The Page Attribute Table (PAT) extends the IA-32 architecture’s page-table format to allow memory types to be assigned to regions of physical memory based on linear address mappings. The PAT is a companion feature to the MTRRs; that is, the MTRRs allow mapping of memory types to regions of the physical address space, where the PAT allows mapping of memory types to pages within the linear address space. The MTRRs are useful for statically describing memory types for physical ranges, and are typically set up by the system BIOS. The PAT extends the functions of the PCD and PWT bits in page tables to allow all five of the memory types that can be assigned with the MTRRs (plus one additional memory type) to also be assigned dynamically to pages of the linear address space.
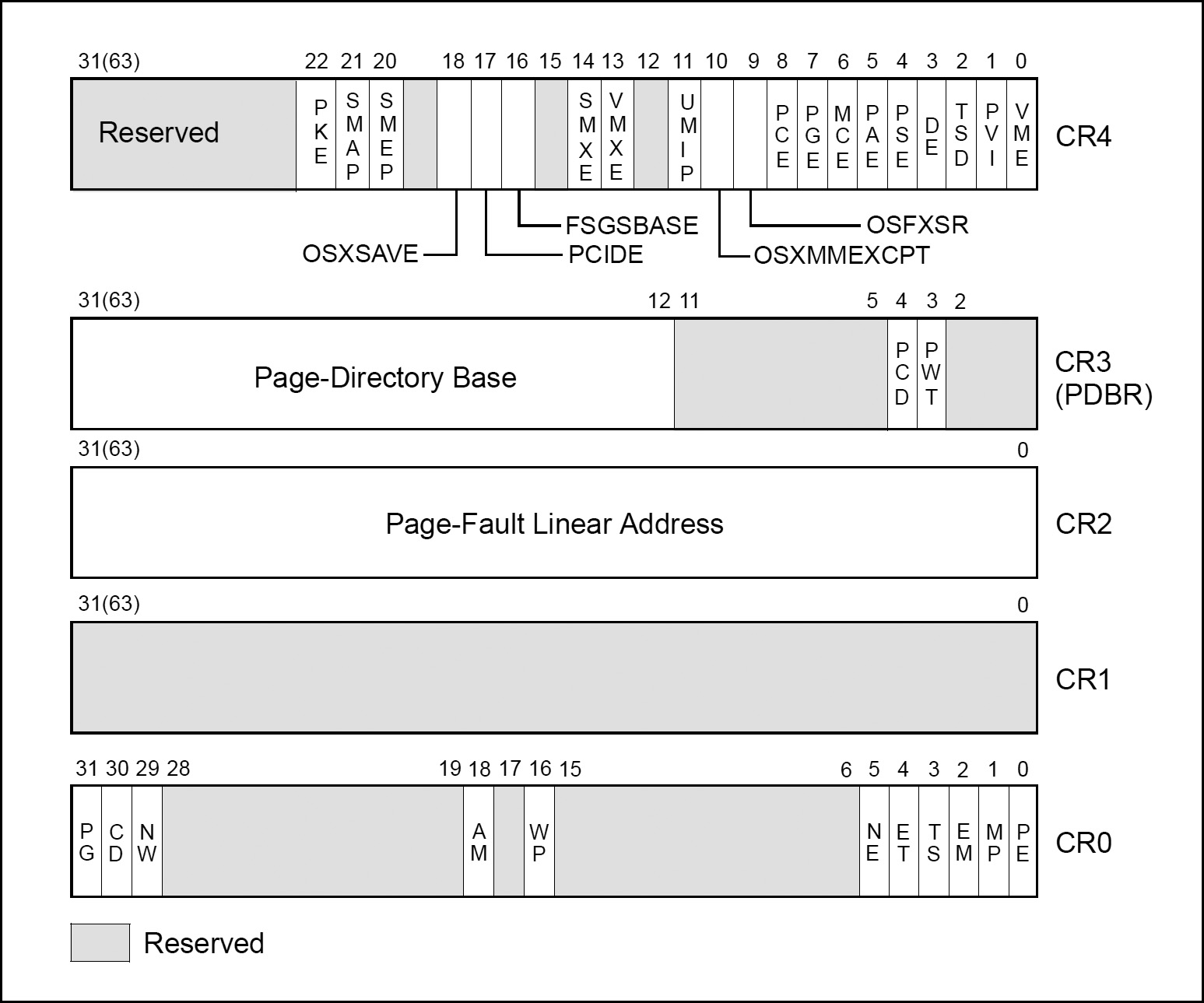
CPU Control Registers
Generally speaking, control registers (CR0, CR1, CR2, CR3, and CR4) determine operating mode of the processor and the characteristics of the currently executing task. These registers are 32 bits in all 32-bit modes and compatibility mode. In 64-bit mode, control registers are expanded to 64 bits.
The MOV CRn instructions are used to manipulate the register bits. These instructions can be executed only when the current privilege level is 0.
Instruction
64-bit Mode
Legacy Mode
Description
MOV r32, CR0–CR7
–
Valid
Move control register to r32.
MOV r64, CR0–CR7
Valid
–
Move extended control register to r64.
MOV r64, CR8
Valid
–
Move extended CR8 to r64.
MOV CR0–CR7, r32
–
Valid
Move r32 to control register.
MOV CR0–CR7, r64
Valid
–
Move r64 to extended control register.
MOV CR8, r64
Valid
–
Move r64 to extended CR8.
Tip: When loading control registers, programs should not attempt to change the reserved bits; that is, always set reserved bits to the value previously read. An attempt to change CR4’s reserved bits will cause a general protection fault. Reserved bits in CR0 and CR3 remain clear after any load of those registers; attempts to set them have no impact.
The Intel 64 and IA-32 architectures provide the following cache-control registers and bits for use in enabling or restricting caching to various pages or regions in memory:
CD flag (bit 30 of control register CR0): Controls caching of system memory locations. If the CD flag is clear, caching is enabled for the whole of system memory, but may be restricted for individual pages or regions of memory by other cache-control mechanisms. When the CD flag is set, caching is restricted in the processor’s caches (cache hierarchy) for the P6 and more recent processor families. With the CD flag set, however, the caches will still respond to snoop traffic. Caches should be explicitly flushed to insure memory coherency. For highest processor performance, both the CD and the NW flags in control register CR0 should be cleared. To insure memory coherency after the CD flag is set, the caches should be explicitly flushed. (Setting the CD flag for the P6 and more recent processor families modify cache line fill and update behaviour. Also, setting the CD flag on these processors do not force strict ordering of memory accesses unless the MTRRs are disabled and/or all memory is referenced as uncached.)
NW flag (bit 29 of control register CR0): Controls the write policy for system memory locations. If the NW and CD flags are clear, write-back is enabled for the whole of system memory, but may be restricted for individual pages or regions of memory by other cache-control mechanisms.
PCD and PWT flags (in paging-structure entries): Control the memory type used to access paging structures and pages.
PCD and PWT flags (in control register CR3): Control the memory type used to access the first paging structure of the current paging-structure hierarchy.
G (global) flag in the page-directory and page-table entries: Controls the flushing of TLB entries for individual pages.
PGE (page global enable) flag in control register CR4: Enables the establishment of global pages with the G flag.
Memory type range registers (MTRRs): Control the type of caching used in specific regions of physical memory.
Page Attribute Table (PAT) MSR: Extends the memory typing capabilities of the processor to permit memory types to be assigned on a page-by-page basis.
3rd Level Cache Disable flag (bit 6 of IA32_MISC_ENABLE MSR): Allows the L3 cache to be disabled and enabled, independently of the L1 and L2 caches. (Available only in processors based on Intel NetBurst microarchitecture)
KEN# and WB/WT# pins (Pentium processor): Allow external hardware to control the caching method used for specific areas of memory. They perform similar (but not identical) functions to the MTRRs in the P6 family processors.
PCD and PWT pins (Pentium processor): These pins (which are associated with the PCD and PWT flags in control register CR3 and in the page-directory and page-table entries) permit caching in an external L2 cache to be controlled on a page-by-page basis, consistent with the control exercised on the L1 cache of these processors. (The P6 and more recent processor families do not provide these pins because the L2 cache is embedded in the chip package.)
How to Manage CPU Cache using Assembly Language
The Intel 64 and IA-32 architectures provide several instructions for managing the L1, L2, and L3 caches. The INVD and WBINVD instructions are privileged instructions and operate on the L1, L2 and L3 caches as a whole. The PREFETCHh, CLFLUSH and CLFLUSHOPT instructions and the non-temporal move instructions (MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, and MOVNTPD) offer more granular control over caching, and are available to all privileged levels.
The INVD and WBINVD instructions are used to invalidate the contents of the L1, L2, and L3 caches. The INVD instruction invalidates all internal cache entries, then generates a special-function bus cycle that indicates that external caches also should be invalidated. The INVD instruction should be used with care. It does not force a write-back of modified cache lines; therefore, data stored in the caches and not written back to system memory will be lost. Unless there is a specific requirement or benefit to invalidating the caches without writing back the modified lines (such as, during testing or fault recovery where cache coherency with main memory is not a concern), software should use the WBINVD instruction.
In theory, WBINVD instruction performs the following steps:
The WBINVD instruction first writes back any modified lines in all the internal caches, then invalidates the contents of both the L1, L2, and L3 caches. It ensures that cache coherency with main memory is maintained regardless of the write policy in effect (that is, write-through or write-back). Following this operation, the WBINVD instruction generates one (P6 family processors) or two (Pentium and Intel486 processors) special-function bus cycles to indicate to external cache controllers that write-back of modified data followed by invalidation of external caches should occur. The amount of time or cycles for WBINVD to complete will vary due to the size of different cache hierarchies and other factors. As a consequence, the use of the WBINVD instruction can have an impact on interrupt/event response time.
The PREFETCHh instructions allow a program to suggest to the processor that a cache line from a specified location in system memory be prefetched into the cache hierarchy.
The CLFLUSH and CLFLUSHOPT instructions allow selected cache lines to be flushed from memory. These instructions give a program the ability to explicitly free up cache space, when it is known that cached section of system memory will not be accessed in the near future.
The non-temporal move instructions (MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, and MOVNTPD) allow data to be moved from the processor’s registers directly into system memory without being also written into the L1, L2, and/or L3 caches. These instructions can be used to prevent cache pollution when operating on data that is going to be modified only once before being stored back into system memory. These instructions operate on data in the general-purpose, MMX, and XMM registers.
How to Disable Hardware Caching
To disable the L1, L2, and L3 caches after they have been enabled and have received cache fills, perform the following steps:
1.) Enter the no-fill cache mode. (Set the CD flag in control register CR0 to 1 and the NW flag to 0.
2.) Flush all caches using the WBINVD instruction.
3.) Disable the MTRRs and set the default memory type to uncached or set all MTRRs for the uncached memory type.
The caches must be flushed (step 2) after the CD flag is set to insure system memory coherency. If the caches are not flushed, cache hits on readswill still occur and data will be read from valid cache lines.
The intent of the three separate steps listed above address three distinct requirements:
a.) Discontinue new data replacing existing data in the cache,
b.) Ensure data already in the cache are evicted to memory,
c.) Ensure subsequent memory references observe UC memory type semantics. Different processor implementation of caching control hardware may allow some variation of software implementation of these three requirements.
Setting the CD flag in control register CR0 modifies the processor’s caching behaviour as indicated, but setting the CD flag alone may not be sufficient across all processor families to force the effective memory type for all physical memory to be UC nor does it force strict memory ordering, due to hardware implementation variations across different processor families. To force the UC memory type and strict memory ordering on all of physical memory, it is sufficient to either program the MTRRs for all physical memory to be UC memory type or disable all MTRRs.
Tip: For the Pentium 4 and Intel Xeon processors, after the sequence of steps given above has been executed, the cache lines containing the code between the end of the WBINVD instruction and before the MTRRS have actually been disabled may be retained in the cache hierarchy. Here, to remove code from the cache completely, a second WBINVD instruction must be executed after the MTRRs have been disabled.
References:
Richard Blum, “Professional Assembly Language”, Wrox Publishing – (2005)
Keith Cooper & Linda Torczon, “Engineering A Compiler”, Morgan Kaufmann, 2nd Edition – (2011)
On the 30th of October at 08:15, the courtyard of Conservatoire National des Arts et Métiers (CNAM) was softly lit by a heart-warming morning sun, occluded by grey Parisien clouds. Just like a cool Morrissey tune; no rain, no cold, no rush. Pure tranquility… At the womb of Art and Science, I somehow felt at home.
As I was wandering around the registration tent and looking at the statues of worldwide known scientists, I bumped into an elderly British gentleman, who was also wandering around alone. We looked at each other for a moment. With a gentle smile, I said “Good morning Mr. Livingstone. Such a great pleasure meeting you, again, Sir!”. As I reminded him who I was, we instantly started talking about the good-old days at Core Design (Derby), and the heydays of 8/16-bit video game development in UK for sure. – What a privilege! For a moment, I thought time stood still.
As the chit-chat and laughter started to peak, I have noticed that we were surrounded by a bunch of young game developers, carefully listening to Mr. Ian Livingstone… Well, it’s quite normal. One does not simply bump into ‘a living legend’ everyday!
Révérence!
Sir Ian Livingstone –yes, he has been knighted once or twice!– is one of the founding fathers of the UK games industry. He is the co-creator of Dungeons & Dragons RPG franchise, author of Fighting Fantasy RPG books, game designer and board member of Domark, co-founder and chairman of Eidos (the company that acquired Core Design and started the Lara Croft:Tomb Raider franchise), and winner of a BAFTA Special Award! In the Wired 100 list for 2012, he was ranked the 16th most influential person in the UK’s digital economy… Now, you know what I mean by ‘a living legend’.
When he asked what I had been doing nowadays, I replied with a witty smile: “Nothing new. Same video game development thing for the last 32 years, Sir!”. We all laughed. He pointed at me and said “Look, we have a newcomer here!”. We all laughed, again… As he kindly looked into my eyes, I knew he was going to switch to something serious: “You know what, after all those years it’s time to start your own company, Mert!”. I gently bowed, and replied “One day I certainly will. Thank you, Sir! For now, I would like to keep on freelancing as much as I can”. He kindly nodded and smiled, as no one in the video game business knows the meaning of ‘freedom’ better than him. I thanked him again for his kind advice and understanding.
When the conversion was over, I felt like I was blessed by the God of video game business. I was relieved to see everything I have done in 3 decades was approved with a gentle nod. That means a lot to me. Relieved, by all means. – (Now, what would you call that; coincidence or destiny?)
The funny thing is, right after the conversation, I realized how young developers were strangely looking at me while whispering to each other: “Well then, who the hell is this long-haired mortal punk chit-chatting with the almighty Sir Livingstone?!” 🙂
Keynotes and Performances
Featuring two days of talks around creative industries, community support, and tools & technologies, there was something for everyone, from experienced designers and veteran artists to folks just getting started.
For me, the highlights of the meetings were;
“Life is a Game” – Ian Livingstone “How Not To Kill Your Art Director” – Vincent Gault “How Not to Go Bankrupt” – Cliff Harris “The Late Game” – Brie Code
All meetings were held at the authentic Conservatoire National des Arts et Métiers (CNAM) amphitheatres, the largest of which can accomodate an audience of 750. These amphitheatres are still heavily used today, as CNAM offers a doctoral degree-granting higher education establishment and Grande école in engineering, operated by the French government, dedicated to providing education and conducting research for the promotion of science and industry. It is a continuing education school for adults seeking engineering (multidisciplinary scientific program) and business degrees, proposing evening classes in a variety of topics.
Show & Tell Demo Area
It was certainly worth visiting each and every indie game developer at the demo area. Bringing young talents and industry veterans together is a step forward for developing better games. We learn from each other. No matter how experienced you are in the global game development industry, there is (and will always be) more to learn. It is in the nature of video game development business.
On the Way Home…
After 2 days full of playing games, meeting game developers and attending various game related events, it was time to go home – yep, for game development! The thing is, I wasn’t aware of the surprise waiting for me at Paris Charles de Gaulle Airport.
Even more games!!! 🙂
In case you wonder, here is the full list of locations you can play Sony PlayStation 4 games -free of charge- at Paris CDG Airport.
Terminal 1: Satellites 1, 3, 4, 5, 6 and 7 Terminal 2: Gates A39, C85, D40 and D66 Terminal 2E: Hall K Gates K36, K43 and K49 Terminal 2E: Hall L Gates L22, L25 and L45 Terminal 2E: Hall M Gates M25 and M45 Terminal 2F: Gates F22 and F46 Terminal 3: International boarding lounge
Nowadays, I’m reading a tiny HarperCollins book called “Blood, Sweat, and Pixels”, written by Jason Schreier.
It is a journey through ‘development hell’ – a media industry jargon for a project that remains in development (often moving between different crews, scripts, or studios) without progressing to completion. In other words, ‘a never-ending project’.
So, if you have ever wondered what it takes to be a video game developer, don’t read this book! It must be the very last introductory document you should be referring to. – Just kidding! 😉
“If I ascend up into heaven, you are there: if I make my bed in hell, behold, you are there.” – (Psalm 139:8)
Jason Schreier takes readers on a fascinating odyssey behind the scenes of video game development. Ultimately, a tribute to the dedicated diehards and unsung heroes who scale mountains of obstacles in their quests to create the best games imaginable.
Life is hard for video game developers. Very hard, indeed… Thanks to nice small touches and heavenly surprises, life is more bearable. This book is certainly one of them. Thank you Jason!
Back to coding… 😉
The Blog of Mert Börü: Selected Works, Ongoing Projects, and Memories